Glide 源码探究 前言 Glide 是安卓平台上媒体管理和图片加载框架,它内部封装了媒体解码工具、内存和磁盘缓存以及资源池等,并向用户暴露简单易用的接口。我们可以用它来获取、解码、并展示视频、图片和 GIF 动画。如果大家有用过 Picasso 应该知道,Glide 的使用方式和 Picasso 非常相似,甚至很多 API 的名称都一样。但是相比 Picasso,Glide 的功能更加强大,内部实现也更加复杂。接下来我们就从源码的角度来探究一下 Glide 的内部原理。
Glide 的简单使用 在探究 Glide 的原理之前,我们先熟悉一下它的常见 API,这样有助于我们后面的分析。Glide 的 API 使用了流式 API 风格,加载图片一行代码就能搞定:
1 Glide.with(context).load(url).into(imageView);
当然,以上只是 Glide 最基础、最常见的用法,它的功能远不止于此,基本上关于图片加载的需求它都能满足。上面这行代码调用了三次方法,经历了三个不同的过程:with() 方法用来获取 RequestManager;load() 方法根据传入的 url 返回了一个 RequestBuilder 对象;into() 方法创建了图片加载请求对象 Request 并开启了加载工作。现在,我们就来分析这三个过程。
Glide 原理 获取 RequestManager Glide 的 with(Context) 方法返回的不是 Glide 实例,而是一个 RequestManager 对象,顾名思义,它用来管理图片加载请求。with() 方法有多个重载,除了接受 Context,它还可以接受 Activity,Fragment,View 等对象,这些重载方法如下:
[->Glide.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public static RequestManager with (Context context) { return getRetriever(context).get(context); } public static RequestManager with (Activity activity) { return getRetriever(activity).get(activity); } public static RequestManager with (android.app.Fragment fragment) { return getRetriever(fragment.getActivity()).get(fragment); } public static RequestManager with (View view) { return getRetriever(view.getContext()).get(view); }
上面这几个重载方法长得都差不多,结果都是返回一个 RequestManager 对象。这个过程分为两步:先通过 getRetriver() 获取一个 RequestManagerRetriever 对象,再通过这个对象的 get() 方法来获取 RequestManager。先看下 getRetriver() 方法:
[->Glide.java]
1 2 3 4 private static RequestManagerRetriever getRetriever (@Nullable Context context) { ...... return Glide.get(context).getRequestManagerRetriever(); }
静态方法 Glide#get() 创建了 Glide 单例,然后通过它的 getRequestManagerRetriever() 返回一个 RequesetManagerRetriever 对象。RequestManagerRetriever 顾名思义,是用来获取 ReqeustManager 的,那么它是怎样得到 RequestManager 对象的呢?我们先来分析下它的一个参数类型为 Context 的 get() 重载方法 :
[->RequestManagerRetriever.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public RequestManager get (Context context) { if (context == null ) { throw new IllegalArgumentException ("You cannot start a load on a null Context" ); } else if (Util.isOnMainThread() && !(context instanceof Application)) { if (context instanceof FragmentActivity) { return get((FragmentActivity) context); } else if (context instanceof Activity) { return get((Activity) context); } else if (context instanceof ContextWrapper) { return get(((ContextWrapper) context).getBaseContext()); } } return getApplicationManager(context); }
这个方法最终会转调两类方法:一是 get() 重载方法,二是 getApplicationManager()。调用 get() 方法的时机是:当前线程在主线程,并且 Context 的实际类型为 FragmentActivity,Activity 和 ContextWrapper 其中之一。其他情况下都会调用 getApplicationManager()。我们看看 get(Activity):
[->RequestManagerRetriever.java]
1 2 3 4 5 6 7 8 9 public RequestManager get (Activity activity) { if (Util.isOnBackgroundThread()) { return get(activity.getApplicationContext()); } else { assertNotDestroyed(activity); android.app.FragmentManager fm = activity.getFragmentManager(); return fragmentGet(activity, fm, null ); } }
如果当前线程是后台线程,会再次调用 get(Context) 方法,因为传入的 Context 是 ApplicationContext,因此这个方法最终会调用 getApplicationManager(Context);如果不是后台线程,在 Activity 还没销毁的前提下,会调用 fragmentGet()。get(FragmentActivity) 的逻辑和 get(Activity) 类似,这里就不赘述了,有兴趣可以自行查看源码。
假设加载动作发生在主线程,fragmentGet() 会得到调用,其源码如下:
[->RequestManagerRetriever.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 private RequestManager fragmentGet (Context context, android.app.FragmentManager fm, android.app.Fragment parentHint) { RequestManagerFragment current = getRequestManagerFragment(fm, parentHint); RequestManager requestManager = current.getRequestManager(); if (requestManager == null ) { Glide glide = Glide.get(context); requestManager = factory.build(glide, current.getGlideLifecycle(), current.getRequestManagerTreeNode()); current.setRequestManager(requestManager); } return requestManager; } RequestManagerFragment getRequestManagerFragment ( final android.app.FragmentManager fm, android.app.Fragment parentHint) { RequestManagerFragment current = (RequestManagerFragment) fm.findFragmentByTag(FRAGMENT_TAG); if (current == null ) { current = pendingRequestManagerFragments.get(fm); if (current == null ) { current = new RequestManagerFragment (); current.setParentFragmentHint(parentHint); pendingRequestManagerFragments.put(fm, current); fm.beginTransaction().add(current, FRAGMENT_TAG).commitAllowingStateLoss(); handler.obtainMessage(ID_REMOVE_FRAGMENT_MANAGER, fm).sendToTarget(); } } return current; }
通过上面的代码可以知道,get(Activity) 方法的逻辑是从当前 Activity 中找 RequestManagerFragment,有则从其中取出 RequestManager,无则创建一个ReqeustManagerFragment 和 RequestManager,将 RequestManagerFragment 和 RequestManager 关联之后把 RequestManager 对象返回。这里有一个比较奇怪的地方:为什么要创建 RequestManagerFragment?我们看下 RequestManagerFragment 的文档说明:
A view-less {@link android.app.Fragment} used to safely store an {@link
通过文档可知,其实 Glide 在这里使用了 “奇技淫巧”,它借助 RequestManagerFragment 来跟踪 Activity 或者 Fragment 的生命周期。为什么要这么做呢?这要从图片加载的场景来理解。本着减少网络请求及各种资源消耗的目的,通常我们会希望如果当前界面被覆盖或者被销毁,图片是不进行加载的。而图片加载库如何能感知界面被覆盖和被销毁呢?我们知道 Activity 或者 Fragment 的生命周期其实和交互界面的变化是相关联的,因此可以利用 Activity 或者 Fragment 的生命周期来驱动图片的加载过程,比如可以在 onStart() 方法中开始图片加载,在 onStop() 方法中暂停图片的加载。然而,如果要在客户端代码中的每一个 Activity 或者 Fragment 中加入这些逻辑,首先代码显得混乱、冗余;其次将图片的加载管理交给开发者实现,增加了开发者的工作,开发者必须实现一套行之有效的图片加载管理方案,这显然不是一个优秀的图片加载库应该做的事。那怎么办呢?这时候 RequestManagerFragment 就派上用场了,如果将 RequestManagerFragment 动态添加入当前的 Activity 或者 Fragment 中,那么 RequestManagerFragment 也将获得生命周期,就可以用 RequestManagerFragment 生命周期来驱动 Glide 的加载。RequestManagerRetriever 的所有 get() 方法,其实都在做同一件事情:根据传入的参数找到当前加载环境关联的 Activity 或者 Fragment,然后设法将 RequesManagerFragment 嵌入其中,最后返回具备生命周期的 RequestManager。我们可以通过 get(View) 来进一步验证:
[->RequestManagerRetriever.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public RequestManager get (@NonNull View view) { if (Util.isOnBackgroundThread()) { return get(view.getContext().getApplicationContext()); } Preconditions.checkNotNull(view); Preconditions.checkNotNull(view.getContext(), "Unable to obtain a request manager for a view without a Context" ); Activity activity = findActivity(view.getContext()); if (activity == null ) { return get(view.getContext().getApplicationContext()); } if (activity instanceof FragmentActivity) { Fragment fragment = findSupportFragment(view, (FragmentActivity) activity); return fragment != null ? get(fragment) : get(activity); } android.app.Fragment fragment = findFragment(view, activity); if (fragment == null ) { return get(activity); } return get(fragment); }
get(View) 会取出 View 中的 Context 进行判断,如果 Context 没有关联到 Activity 或 Fragment 或者图片加载动作发生在后台,那么会调用 get(Context),因为传入的是 Context 是 ApplicationContext,因此最终会调用 getApplicationManager()。如果 View 直接关联到 Activity,那么会调用 get(Activity) 或者 get(FragmentActivity) ,如果是直接关联到 Fragment 便会调用 get(Fragment)。
这样看来,每个 Activity 和 Fragment 都会有一个 RequestManagerFragment(前提是有图片加载动作),而每一个 RequestManagerFragment 都关联着一个 RequestManager。也就是说,每一个 Activity 或者 Fragment 都对应着一个 RequestManager。那么 RequestManager 是如何获取生命周期的呢?上面的 fragmentGet() 中有这样一行代码:
[->RequestManagerRetriever.java]
1 2 requestManager = factory.build(glide, current.getGlideLifecycle(), current.getRequestManagerTreeNode());
这行代码是赋予 RequestManager 生命周期的核心方法。factory 的实际类型是 GeneratedRequestManagerFactory,current 是 RequestManagerFragment 对象,getGlideLifecycle() 方法返回的是 ActivityFragmentLifecycle 对象,它实现了 Lifecycle 接口。
[->RequestManagerFragment.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 ActivityFragmentLifecycle getGlideLifecycle () { return lifecycle; } class ActivityFragmentLifecycle implements Lifecycle { private final Set<LifecycleListener> lifecycleListeners = Collections.newSetFromMap(new WeakHashMap <LifecycleListener, Boolean>()); private boolean isStarted; private boolean isDestroyed; @Override public void addListener (LifecycleListener listener) { lifecycleListeners.add(listener); if (isDestroyed) { listener.onDestroy(); } else if (isStarted) { listener.onStart(); } else { listener.onStop(); } } @Override public void removeListener (LifecycleListener listener) { lifecycleListeners.remove(listener); } void onStart () { isStarted = true ; for (LifecycleListener lifecycleListener : Util.getSnapshot(lifecycleListeners)) { lifecycleListener.onStart(); } } void onStop () { isStarted = false ; for (LifecycleListener lifecycleListener : Util.getSnapshot(lifecycleListeners)) { lifecycleListener.onStop(); } } void onDestroy () { isDestroyed = true ; for (LifecycleListener lifecycleListener : Util.getSnapshot(lifecycleListeners)) { lifecycleListener.onDestroy(); } } }
Lifecycle 是一个管理生命周期监听器的接口。ActivityFragmentLifecycle 在实现接口的基础上增加了三个生命周期方法,它们会遍历所有的 LifecycleListener,调用其相应的生命周期方法。这三个方法主要是用来和 RequestManagerFragment 的生命周期对接:
[->RequestManagerFragment.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Override public void onStart () { super .onStart(); lifecycle.onStart(); } @Override public void onStop () { super .onStop(); lifecycle.onStop(); } @Override public void onDestroy () { super .onDestroy(); lifecycle.onDestroy(); unregisterFragmentWithRoot(); }
因此,任何实现 LifecycleListener 的类可通过 addListener() 添加到 ActivityFragmentLifecycle 中从而获得生命周期。那么我们可以猜测 RequestManager 一定实现了 LifecycleListener 接口,事实也的确如此。那么 RequestManager 是如何添加进 ActivityFragmentLifecycle 中的呢? 答案就在 RequestManager 的构造方法中:
[->RequestManager.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 RequestManager( Glide glide, Lifecycle lifecycle, RequestManagerTreeNode treeNode, RequestTracker requestTracker, ConnectivityMonitorFactory factory, Context context) { this .glide = glide; this .lifecycle = lifecycle; this .treeNode = treeNode; this .requestTracker = requestTracker; this .context = context; connectivityMonitor = factory.build( context.getApplicationContext(), new RequestManagerConnectivityListener (requestTracker)); if (Util.isOnBackgroundThread()) { mainHandler.post(addSelfToLifecycle); } else { lifecycle.addListener(this ); } lifecycle.addListener(connectivityMonitor); setRequestOptions(glide.getGlideContext().getDefaultRequestOptions()); glide.registerRequestManager(this ); }
这里根据当前线程决定如何将 RequestManager 添加至 Lifecycle 中。如果子线程,通过 post 添加;如果 UI 线程,就直接添加。原因注释里说的很清楚了,如果是 Application 级别的 RequestManager,也就是通过 getApplicationManager() 得到的那个 RequestMangaer,它可能创建于子线程中,那么就有可能冒同步停止和继续请求的风险。其实这段话我也没理解:),等以后上网查资料解决吧。
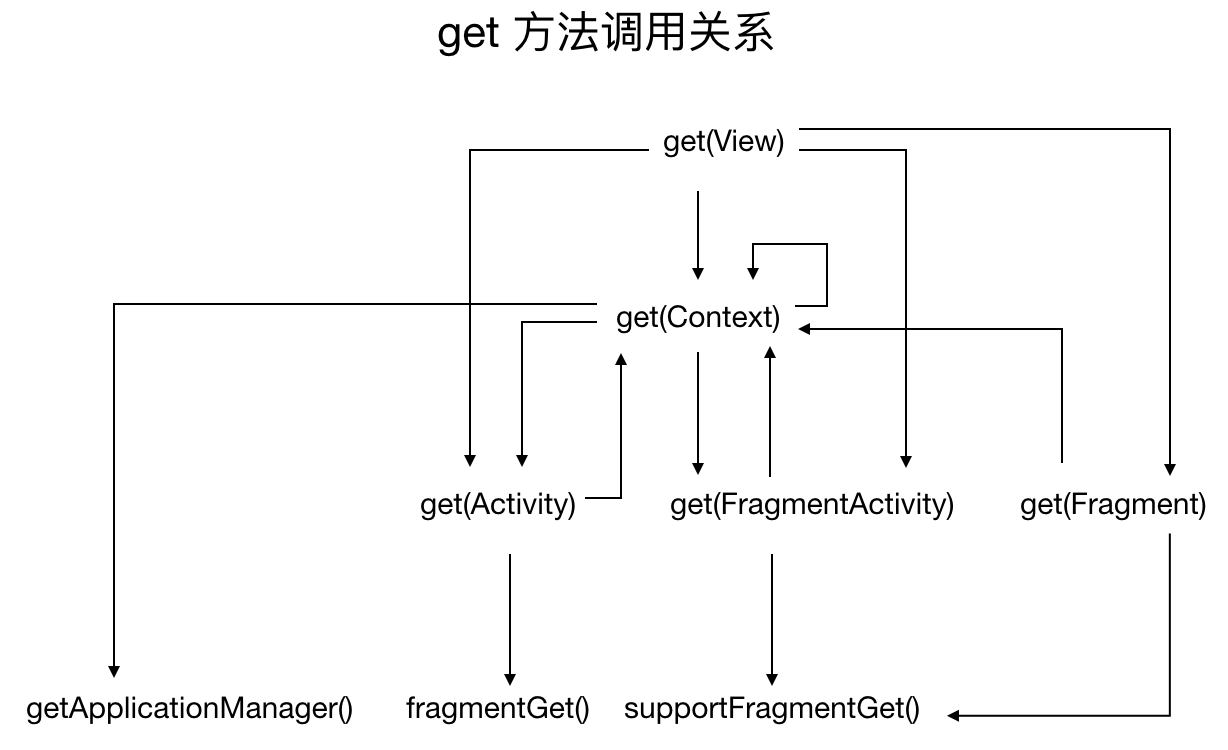
get() 方法之间的调用关系可能有点复杂,贴上一张图便于理解:
从上图可以看出几乎在所有的 get() 重载方法中,都会根据特殊情况直接或间接调用 getApplicationManager() 方法,这种特殊情况就是加载动作发生在后台线程或者无法找到关联的 Activity 或者 Fragment,此方法返回的 RequestManager 是没有生命周期的。这样做的目的是什么呢?我们知道生命周期是在 UI 线程接受回调的,让子线程也接受生命周期回调也不是不可以,但是子线程在加载,UI 线程通过生命周期也介入加载过程,相当于两个线程同时操作数据,这会带来线程安全问题,如果做同步,需要同步的地方很多,那么会带来严重的性能问题;而如果没有关联到 Activity 或者 Fragment,无法接受生命周期回调。对于这两种情况,Glide 没有办法,只能任其加载而不受生命周期控制,算是一种折中了吧。getApplicationManager() 的定义如下:
[->RequestManagerRetriever.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 private RequestManager getApplicationManager (@NonNull Context context) { if (applicationManager == null ) { synchronized (this ) { if (applicationManager == null ) { Glide glide = Glide.get(context.getApplicationContext()); applicationManager = factory.build(glide, new ApplicationLifecycle (), new EmptyRequestManagerTreeNode (), context.getApplicationContext()); } } } return applicationManager; }
这个方法也有这样一行代码:
[->RequestManagerRetriever.java]
1 2 3 applicationManager = factory.build(glide, new ApplicationLifecycle (), new EmptyRequestManagerTreeNode (), context.getApplicationContext());
applicationManager 也是通过 GeneratedRequestManagerFactory#build() 来创建的,但第二个参数和之前的有所不同,这里直接 new 了一个 ApplicationLifecycle() 传进去。ApplicationLifecycle 的定义如下:
[-> ApplicationLifecycle.java]
1 2 3 4 5 6 7 8 9 10 class ApplicationLifecycle implements Lifecycle { @Override public void addListener (LifecycleListener listener) { listener.onStart(); } @Override public void removeListener (LifecycleListener listener) { } }
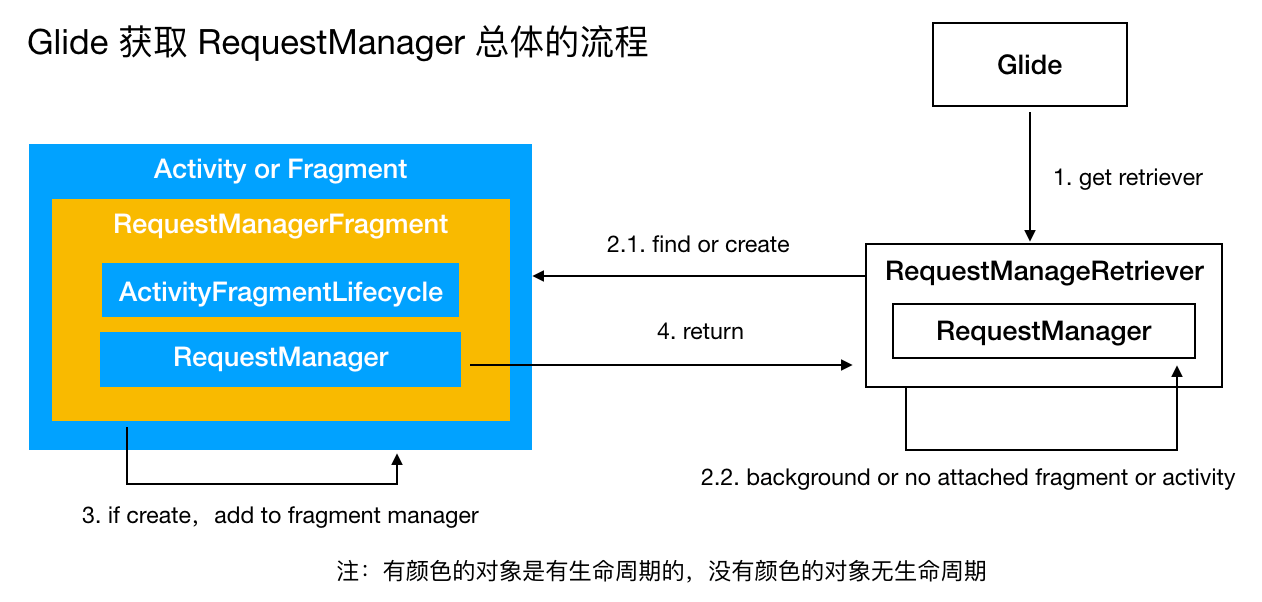
可以看出,这个 ApplicationLifecycle 其实是个假 Lifecycle,因为他根本没有将 LifecycleListener 添加进去,仅仅是立马调用了其 onStart() 方法。由此可见,getApplicationManager() 获取的是没有生命周期的 RequestManager。最后用一张图来总结 RequestManager 的获取过程:
创建 RequestBuilder 前面我们分析了 Request 的获取过程,既然请求管理器建好了,那么下一步肯定是构建请求了。Glide 使用建造者模式来构建 Request,这个构建者就是 RequestBuilder。建造者模式通常是这样的,通过构建器收集参数,最后调用其 build() 或 create() 方法构建目标对象。那么 RequestBuilder 为了构造一个 Request 会收集哪些参数呢?我们看看它的声明的字段:
[->RequestBuilder.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 private final Context context;private final RequestManager requestManager; private final Class<TranscodeType> transcodeClass; private final RequestOptions defaultRequestOptions; private final Glide glide;private final GlideContext glideContext; @NonNull protected RequestOptions requestOptions; @NonNull @SuppressWarnings("unchecked") private TransitionOptions<?, ? super TranscodeType> transitionOptions; @Nullable private Object model;@Nullable private RequestListener<TranscodeType> requestListener; @Nullable private RequestBuilder<TranscodeType> thumbnailBuilder; @Nullable private RequestBuilder<TranscodeType> errorBuilder; @Nullable private Float thumbSizeMultiplier;private boolean isDefaultTransitionOptionsSet = true ;private boolean isModelSet;private boolean isThumbnailBuilt;
我们看下 RequestOptions 这个类,它是请求的附加选项,在发起一个图片请求时,我们可能对它会有一些特殊的要求,此时就可以通过 RequestOptions 来添加这些要求,ReqeustOptions 的定义:
[->RequestOptions.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public class RequestOptions implements Cloneable { private static final int UNSET = -1 ; private static final int SIZE_MULTIPLIER = 1 << 1 ; private static final int DISK_CACHE_STRATEGY = 1 << 2 ; private static final int PRIORITY = 1 << 3 ; private static final int ERROR_PLACEHOLDER = 1 << 4 ; private static final int ERROR_ID = 1 << 5 ; private static final int PLACEHOLDER = 1 << 6 ; private static final int PLACEHOLDER_ID = 1 << 7 ; private static final int IS_CACHEABLE = 1 << 8 ; private static final int OVERRIDE = 1 << 9 ; private static final int SIGNATURE = 1 << 10 ; private static final int TRANSFORMATION = 1 << 11 ; private static final int RESOURCE_CLASS = 1 << 12 ; ...... private int fields; private float sizeMultiplier = 1f ; private DiskCacheStrategy diskCacheStrategy = DiskCacheStrategy.AUTOMATIC; private Priority priority = Priority.NORMAL; private Drawable errorPlaceholder; private int errorId; private Drawable placeholderDrawable; private int placeholderId; private boolean isCacheable = true ; private int overrideHeight = RequestOptions.UNSET; private int overrideWidth = RequestOptions.UNSET; private Key signature = EmptySignature.obtain(); private boolean isTransformationRequired; private boolean isTransformationAllowed = true ; private Drawable fallbackDrawable; private int fallbackId; private Options options = new Options (); private Map<Class<?>, Transformation<?>> transformations = new HashMap <>(); private Class<?> resourceClass = Object.class; ...... }
可以看出,请求的附加选项包括底盘缓存策略,请求优先级,占位图,兜底图等常见选项,这些选项全部通过标志位来标识是否设立新值,为什么通过标志位来表示?因为很多选项都有默认值,通过判空来判断它们是否设定了新值是行不通的。RequestOptions 是可以合并的,两个 RequestOptions 可以合并成一个 RequestOptions,这个功能由 RequestOptions#apply(RequestOptions) 来实现。例如 A 想合并 B,可以这样: C = A.apply(B) ,结果是 B 中的新值会覆盖 A 中的值,B 中的默认值不会覆盖 A 中的值。
现在我们回头再看看 RequestManager 的 load() 方法:
[->RequestManager.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public RequestBuilder<Drawable> load (@Nullable Drawable drawable) { return asDrawable().load(drawable); } public RequestBuilder<Drawable> load (@Nullable Bitmap bitmap) { return asDrawable().load(bitmap); } public RequestBuilder<Drawable> load (@Nullable Object model) { return asDrawable().load(model); } public RequestBuilder<Drawable> asDrawable () { return as(Drawable.class).transition(new DrawableTransitionOptions ()); } public <ResourceType> RequestBuilder<ResourceType> as (Class<ResourceType> resourceClass) { return new RequestBuilder <>(glide, this , resourceClass, context); }
as() 方法构建了一个 RequestBuilder 并指明了 resourceClass,这个 resourceClass 就是 RequestBuilder 中的 transcodeClass,表明图片资源最终转换成的对象。 asDrawable() 方法创建了一个 transcodeClass 为 Drawable 的 RequestBuilder,并且指定了 transitionOptions 的值。而 load() 方法最为最外层的方法,首先调用了 asDrawable(),然后调用 RequestBuilder#load() 将 model 传进去。
[->ReuqestBuilder.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public RequestBuilder<TranscodeType> load (@Nullable Uri uri) { return loadGeneric(uri); } public RequestBuilder<TranscodeType> load (@Nullable File file) { return loadGeneric(file); } public RequestBuilder<TranscodeType> load (@Nullable Drawable drawable) { return loadGeneric(drawable) .apply(diskCacheStrategyOf(DiskCacheStrategy.NONE)); } public RequestBuilder<TranscodeType> apply (@NonNull RequestOptions requestOptions) { Preconditions.checkNotNull(requestOptions); this .requestOptions = getMutableOptions().apply(requestOptions); return this ; } private RequestBuilder<TranscodeType> loadGeneric (@Nullable Object model) { this .model = model; isModelSet = true ; return this ; }
[->RequestOptions.java]
1 2 3 public static RequestOptions diskCacheStrategyOf (@NonNull DiskCacheStrategy diskCacheStrategy) { return new RequestOptions ().diskCacheStrategy(diskCacheStrategy); }
RequestBuilder 中有很多 load() 方法,上面只列举了一部分。以上三个 load() 方法都会转调 loadGeneric() 方法,第三个 load() 还会合并一个指定了磁盘缓存策略的 RequestOptions。loadGeneric() 做的事很简单,就是给 model 赋值。由此我们可以看出,model 的实际类型有很多种,可以是 Uri,也可以是 Bitmap,还可以是 File 等。
RequestBuilder 的参数收集过程讲完了,下一步就是 Request 的构建过程了。从上面的分析可知,RequestManager#load() 方法返回的既然是 RequestBuilder,那 Request 的构建和执行一定都是在 into() 的调用栈中进行的。
Request 的构建和执行 万事俱备,只欠东风。现在我们以 into() 为切入点,看看 Request 是如何构建和执行的。into() 定义在 RequestBuilder 中:
[->RequestBuilder.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public <Y extends Target <TranscodeType>> Y into (@NonNull Y target) { return into(target, null ); } @Synthetic <Y extends Target <TranscodeType>> Y into ( @NonNull Y target, @Nullable RequestListener<TranscodeType> targetListener) { return into(target, targetListener, getMutableOptions()); } public Target<TranscodeType> into (ImageView view) { ...... return into(context.buildImageViewTarget(view, transcodeClass), null , requestOptions); }
into() 有多个重载,但是最终都会调用一个含三个参数的重载方法。第三个 into() 我们很熟悉,我们经常使用它来将加载好的图片资源设置给 ImageView,这个 ImageView 在方法中会被包装成一个 Target 对象,然后传入含三个参数的 into() 重载方法中。Glide 把所有图片资源的目的用途抽象成 Target,这一点很巧妙,因为图片加载库的使用场景有很多,除了可以将它设置给 ImageView,还可以存入磁盘文件,内存,或者其他用途。我们可以看看 Target 的定义:
[->Target.java]
1 2 3 4 5 6 7 8 9 10 public interface Target <R> extends LifecycleListener { void onLoadStarted (@Nullable Drawable placeholder) ; void onLoadFailed (@Nullable Drawable errorDrawable) ; void onResourceReady (@NonNull R resource, @Nullable Transition<? super R> transition) ; void getSize (@NonNull SizeReadyCallback cb) ; void removeCallback (@NonNull SizeReadyCallback cb) ; void setRequest (@Nullable Request request) ; @Nullable Request getRequest () ; }
我们可以根据自己的需要实现 Target 接口,从而自定义图片资源的用途。buildImageViewTarget() 返回的是一个 ImageViewTarget 对象,它是一个抽象类,继承自 ViewTarget,有两个子类 BitmapImageViewTarget 和 DrawableImageViewTarget,前者的接收的图片资源类型是 Bitmap,后者是 Drawable。
[->ImageViewTarget.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 @Override public void onLoadStarted (@Nullable Drawable placeholder) { super .onLoadStarted(placeholder); setResourceInternal(null ); setDrawable(placeholder); } @Override public void onLoadFailed (@Nullable Drawable errorDrawable) { super .onLoadFailed(errorDrawable); setResourceInternal(null ); setDrawable(errorDrawable); } @Override public void onLoadCleared (@Nullable Drawable placeholder) { super .onLoadCleared(placeholder); if (animatable != null ) { animatable.stop(); } setResourceInternal(null ); setDrawable(placeholder); } @Override public void onResourceReady (@NonNull Z resource, @Nullable Transition<? super Z> transition) { if (transition == null || !transition.transition(resource, this )) { setResourceInternal(resource); } else { maybeUpdateAnimatable(resource); } } private void setResourceInternal (@Nullable Z resource) { setResource(resource); maybeUpdateAnimatable(resource); } protected abstract void setResource (@Nullable Z resource) ;
现在看下 RequestBuilder 含三个参数的 into() 方法:
[->RequestBuilder.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 private <Y extends Target <TranscodeType>> Y into ( @NonNull Y target, @Nullable RequestListener<TranscodeType> targetListener, @NonNull RequestOptions options) { Util.assertMainThread(); Preconditions.checkNotNull(target); if (!isModelSet) { throw new IllegalArgumentException ("You must call #load() before calling #into()" ); } options = options.autoClone(); Request request = buildRequest(target, targetListener, options); Request previous = target.getRequest(); if (request.isEquivalentTo(previous) && !isSkipMemoryCacheWithCompletePreviousRequest(options, previous)) { request.recycle(); if (!Preconditions.checkNotNull(previous).isRunning()) { previous.begin(); } return target; } requestManager.clear(target); target.setRequest(request); requestManager.track(target, request); return target; }
buildRequest() 创建了一个 Request,之后会判断这个 target 当前关联的 Request 是不是和这个新的 Request 是不是等效的,如果是,并且 isSkipMemoryCacheWithCompletePreviousRequest() 返回 false,便将这个新的 Request 回收掉,避免一个目标上有多个请求。然后判断之前的那个 Request 是不是还在跑,如果没有,那么就启动它,为什么这样做?注释里已经说的很清楚了,就是为了将当前绑定在 target 上的请求再执行一遍,这样请求完成后会将结果重新传递一遍;如果正在跑,没必要重启这个请求,因为请求完成之后会将结果传递回去。对于 isSkipMemoryCacheWithCompletePreviousRequest() 这个方法,其实有必要分析一下,为什么它返回 false 的时候才能将新的 Request 取消,不过目前为止我还没有完全理解,但还是先贴上这个方法供大家自行理解:
[->RequestBuilder.java]
1 2 3 4 5 6 7 8 9 private boolean isSkipMemoryCacheWithCompletePreviousRequest ( RequestOptions options, Request previous) { return !options.isMemoryCacheable() && previous.isComplete(); }
回到 into() 方法,真正处理加载请求的方法是 RequestManager#track() 方法:
[->RequestManager.java]
1 2 3 4 void track (Target<?> target, Request request) { targetTracker.track(target); requestTracker.runRequest(request); }
RequestManager 中有两个 “追踪器”,一个是 TargetTracker,另一个是 RequestTracker,前者用来管理 target,后者管理 request。由于 TargetTracker 和 Target 都实现了 LifecycleListener 接口,这样生命周期就能从 RequestManager 传到 Target。真正启动请求的方法是 RequestTracker#runRequest() :
[->RequestTracker.java]
1 2 3 4 5 6 7 8 public void runRequest (Request request) { requests.add(request); if (!isPaused) { request.begin(); } else { pendingRequests.add(request); } }
RequestTracker 首先将 request 加入请求列表 requests 中,这个列表保存的是所有请求;然后判断是否需要暂停加载(受生命周期的控制),如果是,则开始请求,否则将这个请求放入待处理队列 pendingRequests 中。为什么要用一个 pendingRequest 来管理这些待处理请求呢?其实并不是为了将他们储存起来待以后执行,而仅仅是为了让他们不被回收。requests 持有的是 Request 的弱引用,如果请求没有马上执行,这些 Request 仅仅被弱引用持有,那么就有被回收的可能,将他们放入 pendingRequests 中就是为了让他们被强引用持有防止被回收。更详细的解释可以看看这个 issue 。
Request 是一个接口,它包含多了很多控制方法和状态查询方法。Request 在当前 Glide 版本中只有一个实现者:SingleRequest。SingleRequest 的 begin() 方法如下:
[->SingleRequest.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 public void begin () { ...... if (Util.isValidDimensions(overrideWidth, overrideHeight)) { onSizeReady(overrideWidth, overrideHeight); } else { target.getSize(this ); } if ((status == Status.RUNNING || status == Status.WAITING_FOR_SIZE) && canNotifyStatusChanged()) { target.onLoadStarted(getPlaceholderDrawable()); } ...... }
begin() 是 Request 的入口方法,它开启了图片请求的处理流程,而整个流程的第一步就是获取期望的图片宽高。第一个 if 语句块,它会判断用户是否显式要求了图片宽高,如果指明了,那么立马执行 onSizeReady(),否则执行 Target#getSize()。onSizeReady() 是 SingleRequest 实现的 SizeReadyCallback 接口中的方法。
[->Target.java]
1 void getSize (@NonNull SizeReadyCallback cb) ;
getSize() 的作用就是用来获取图片的宽高,获取成功之后就通过 SizeReadyCallback#onSizeRady() 将结果返回。Target 是目标用途的抽象,所以图片的宽高理应由它来指定。比如,对于 ViewTarget 来说,它的 getSize() 返回的就是 View 的宽高。这里我们可能就有疑问了,为什么 getSize() 要设计成异步的?其实答案很简单,对于 View 来说,它的宽高只有在 Activity#onResume() 之后才能获取到,严格来说是 View#layout() 之后才能获取到。请求发起时可能 View 的宽高还获取不到,因此将 getSize() 设计成异步的是理所应当的。现在重点是 onSizeReady() :
[->SingleRequest.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 loadStatus = engine.load( glideContext, model, requestOptions.getSignature(), this .width, this .height, requestOptions.getResourceClass(), transcodeClass, priority, requestOptions.getDiskCacheStrategy(), requestOptions.getTransformations(), requestOptions.isTransformationRequired(), requestOptions.isScaleOnlyOrNoTransform(), requestOptions.getOptions(), requestOptions.isMemoryCacheable(), requestOptions.getUseUnlimitedSourceGeneratorsPool(), requestOptions.getUseAnimationPool(), requestOptions.getOnlyRetrieveFromCache(), this );
上面这段代码是 onSizeReady() 的主要逻辑,它调用了 Engine#load(),传入了一些和请求相关的各种参数,这个方法返回的是一个 LoadStatus 对象,关于它我们待会儿再分析。
[->Engine.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 EngineKey key = keyFactory.buildKey(model, signature, width, height, transformations, resourceClass, transcodeClass, options); EngineResource<?> active = loadFromActiveResources(key, isMemoryCacheable); if (active != null ) { cb.onResourceReady(active, DataSource.MEMORY_CACHE); ...... return null ; } EngineResource<?> cached = loadFromCache(key, isMemoryCacheable); if (cached != null ) { cb.onResourceReady(cached, DataSource.MEMORY_CACHE); ...... return null ; } EngineJob<?> current = jobs.get(key, onlyRetrieveFromCache); if (current != null ) { current.addCallback(cb); ...... return new LoadStatus (cb, current); } EngineJob<R> engineJob = engineJobFactory.build(key, isMemoryCacheable, useUnlimitedSourceExecutorPool, useAnimationPool, onlyRetrieveFromCache); DecodeJob<R> decodeJob = decodeJobFactory.build(glideContext, model, key, signature, width, height, resourceClass, transcodeClass, priority, diskCacheStrategy, transformations, isTransformationRequired, isScaleOnlyOrNoTransform, onlyRetrieveFromCache, options, engineJob); jobs.put(key, engineJob); engineJob.addCallback(cb); engineJob.start(decodeJob); ...... return new LoadStatus (cb, engineJob);
Engine#load() 方法的逻辑是:
首先构建出标识这个请求的 Key,这个 Key 用来标识一个请求,Key 相同的 Request 是等效的。可以看出这个 Key 有多个参数组成,只要其中一个参数不同,Key 就不同,那么这个 Request 也就是与众不同的;
然后根据 Key 从 activy resource 中取出 EngineResource,EngineResource 是图片资源在内存中对应的对象,如果能找到,就调用 ResourceCallback#onResourceReady() 将获取的资源传回给 SingleRequest;
如果上个步骤获取的 EngineResource 为 null,那么就从根据 Key 从 cache 中获取,如果能获取到,同样将结果回传;
如果上个步骤获取的还是 null,那么在 jobs 中根据 Key 查找对应的 EngineJob。EngineJob 的作用文档中是这样说的:通过添加和移除回调、在加载任务完成时通知回调来管理一次加载。简单点说就是一次加载任务的回调管理器。如果能找到,便将 ResourceCallback 添加进去,然后返回一个 LoadStatus。这样做的目的就是避免重复请求,因为如果多个请求如果是等效的,没有必要为它们去加载多次,而只需要加载结果到来时逐个通知它们一遍就好。
如果找不到对应的 EngineJob,没办法,只能开个的 EngineJob 了。通过 EngineJobFactory#build() 新建一个 EngineJob 紧接着又通过 DecodeJobFactory#build() 新建了一个 DecodeJob 并将 EngineJob 传进去。DecodeJob 对应的是一个加载任务,当完成加载后会通过 EngineJob 这个回调管理器将结果送回到 SingleRequest 中。
DecodeJob 承包了真正的加载任务,现在我们就从 Engine#start() 开始来分析一下 DecodeJob:
[->EngineJob.java]
1 2 3 4 5 6 7 public void start (DecodeJob<R> decodeJob) { this .decodeJob = decodeJob; GlideExecutor executor = decodeJob.willDecodeFromCache() ? diskCacheExecutor : getActiveSourceExecutor(); executor.execute(decodeJob); }
根据需不需要从磁盘中获取资源,选择不同的线程池来执行资源加载任务。从这里可以看出 DecodeJob 实现了 Runnable 接口,因此资源加载逻辑应该全部在它的 run() 方法中:
[->DecodeJob.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 @Override public void run () { ...... DataFetcher<?> localFetcher = currentFetcher; try { if (isCancelled) { notifyFailed(); return ; } runWrapped(); } catch (Throwable t) { ...... if (stage != Stage.ENCODE) { throwables.add(t); notifyFailed(); } if (!isCancelled) { throw t; } } finally { if (localFetcher != null ) { localFetcher.cleanup(); } TraceCompat.endSection(); } }
其执行逻辑是:如果状态为 cancelled,或者任务执行时出现异常,那么就发出任务失败的通知;否则执行 runWrapper() 方法。
[->DecodeJob.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 private void runWrapped () { switch (runReason) { case INITIALIZE: stage = getNextStage(Stage.INITIALIZE); currentGenerator = getNextGenerator(); runGenerators(); break ; case SWITCH_TO_SOURCE_SERVICE: runGenerators(); break ; case DECODE_DATA: decodeFromRetrievedData(); break ; default : throw new IllegalStateException ("Unrecognized run reason: " + runReason); } }
runWrapper() 方法会根据 runReason 的值执行不同的分支。runReason 的初始值是 INITIALIZE,INITIALIZE 这条分支做的事是:
通过 getNextStage() 获取下一个 Stage,Stage 用来表明当前的工作阶段;
通过 getNextGenerator() 获取下一个 DataFetcherGenerator,DataFetcherGenerator 顾名思义使用来产生 DataFethcer 的,关于 DataFetcher 及其作用之后会详细分析;
执行 runGenerators()。
getNextStage() 的定义如下:
[->DecodeJob.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 private Stage getNextStage (Stage current) { switch (current) { case INITIALIZE: return diskCacheStrategy.decodeCachedResource() ? Stage.RESOURCE_CACHE : getNextStage(Stage.RESOURCE_CACHE); case RESOURCE_CACHE: return diskCacheStrategy.decodeCachedData() ? Stage.DATA_CACHE : getNextStage(Stage.DATA_CACHE); case DATA_CACHE: return onlyRetrieveFromCache ? Stage.FINISHED : Stage.SOURCE; case SOURCE: case FINISHED: return Stage.FINISHED; default : throw new IllegalArgumentException ("Unrecognized stage: " + current); } }
该方法根据当前的 Stage 返回下一个 Stage,它的状态变迁可以用下图来表示:
getNextGenerator() 的定义如下:
[->DecodeJob.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 private DataFetcherGenerator getNextGenerator () { switch (stage) { case RESOURCE_CACHE: return new ResourceCacheGenerator (decodeHelper, this ); case DATA_CACHE: return new DataCacheGenerator (decodeHelper, this ); case SOURCE: return new SourceGenerator (decodeHelper, this ); case FINISHED: return null ; default : throw new IllegalStateException ("Unrecognized stage: " + stage); } }
这个方法根据当期的 Stage 返回不同的 DataFetcherGenerator,DataFetcherGenerator 的作用是用注册的 ModelLoader 和 Model 产生 DataFetcher 来加载数据。读到这里大家可能有点难理解,因此,在继续深入下去之前,我们有必要了解下 DecodeJob 加载图片资源的整个过程以及 Model,ModelLoader,DataFetcher 等类的的角色和作用,这样有助于后面的分析和理解。
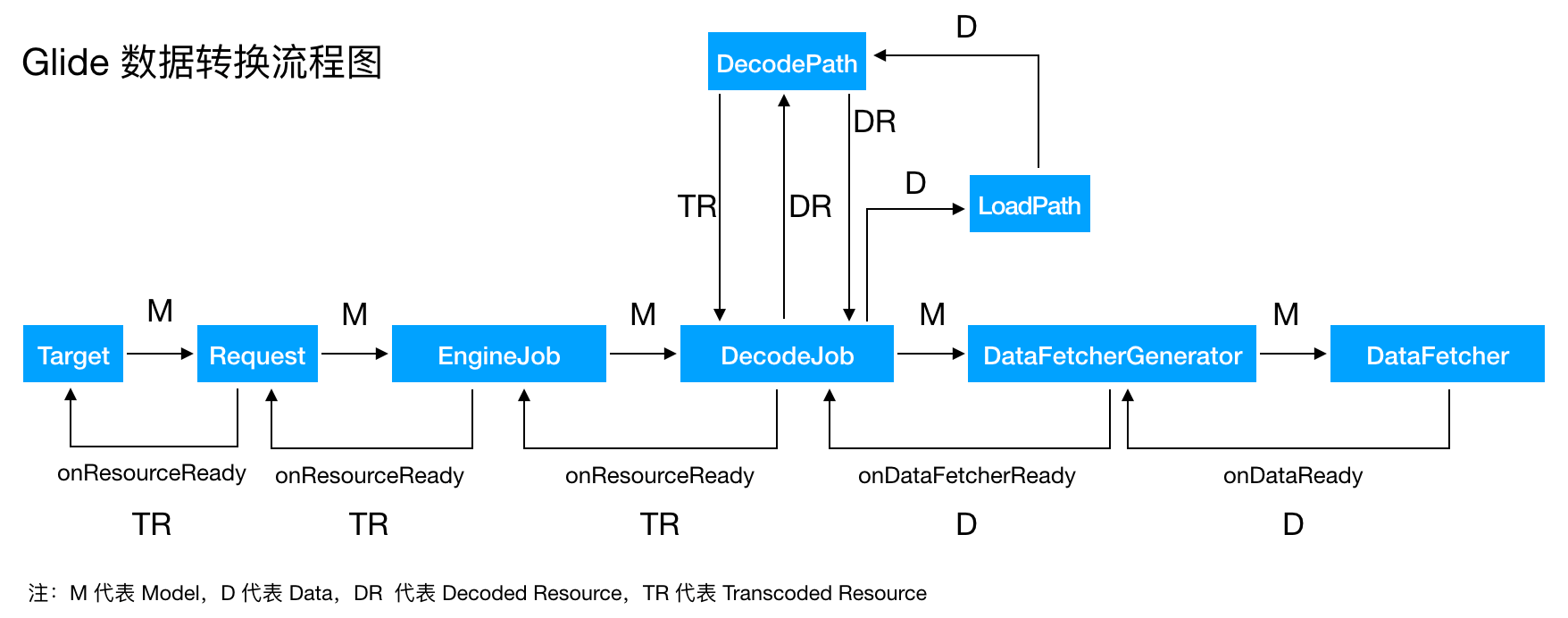
首先我们了解一下 DecodeJob 加载资源的流程,DecodeJob 加载资源的过程中资源类型的变化可以这样来表示:
Model => Data => Decoded Resource => Transcoded Resource 。
Model 一开始是通过 RequestManager#load() 穿过来的,它的类型可以有很多种,它可以是 String,Uri,Drawable,Bitmap,byte[]等。我们可以把它理解成图片加载过程的初始对象;
Data 是原始的数据流,它一般以二进制的形式存在,例如 InputStream,ByteBuffer,byte[]。但也不绝对是二进制流,它也可以是 Bitmap,Drawble 等资源对象,这样看 Model 传入的初始对象是什么;
Decode Resource 是解码好的图片对象,例如 Bitmap,GitDrawable 等;
Transcoded Resource 是最终期望的图片资源类型,它的类型和 RequestBuilder#as() 接受的类型以及 Target 可接受的类型是保持一致的,也就是说这个类型就是“目标类型”,它的类型可以有很多,比如 Bitmap,Drawable,byte[] 等。
如果我们传入的 model 为一个 Uri,而我们的目标类型为 Bitmap 时,Glide 是如何处理的呢?首先,Glide 会将 String(Model) 转换成 InputStream(Data),再将 InputStream(Data)转换成 Bitmap(Decoded Resource),最后再由 Bitmap(Decoded Resource)到 Bitmap(Transcoded Resource)。其实 Decode Resource 到 Transcoded Resource 资源的类型是一样的,因此 Glide 其实不会做任何事。
同理,如果我们传入的 model 是一个 Bitmap,目标类型也是 Bitmap 类型时,由于资源类型至始至终都没有发生变化,那么 Data,Decoded Resource,Transocded Resource 的类型都是 Bitmap。你会说这有什么意义呢?我们知道整个加载流程发生变化的不仅仅是资源类型,还有资源的尺寸等。我们的确可以直接通过 ImageView#setImageBitmap() 方法将一张 Bitmap 设置给 ImageView,但是忽略 ImageView 的大小而将 Bitmap 以原始尺寸显示是很浪费内存的。通常我们会对 Bitmap 进行压缩,必要的话还需要将压缩后的图片进行缓存,如果不利用 Glide,这将是一件很麻烦的是事,而 Glide 使得这个过程的工作量大大减少。
在加载过程中,资源的类型的变化是由 Glide 中特定的对象来完成的,例如 Model 到 Data 的转化就是 ModelLoader 来完成的,Data 到 Decoded Resource 的转换是由 ResourceDecoder 完成的,Decoded Resource 到 Transcoded Resource 的过程是由 ResourceTranscoder 来完成的。以上三者都只是接口,它们在 Glide 由许许多多的实现类,每个实现类都完成特定的两种资源类型的转换,比如 HttpUrlLoader 是一个 ModelLoader,它完成 Uri(Model) 到 InputStream(Data) 的转换过程。
现在我们来看下 ModelLoader 的定义吧:
[->ModelLoader.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public interface ModelLoader <Model, Data> { class LoadData <Data> { public final Key sourceKey; public final List<Key> alternateKeys; public final DataFetcher<Data> fetcher; public LoadData (@NonNull Key sourceKey, @NonNull DataFetcher<Data> fetcher) { this (sourceKey, Collections.<Key>emptyList(), fetcher); } public LoadData (@NonNull Key sourceKey, @NonNull List<Key> alternateKeys, @NonNull DataFetcher<Data> fetcher) { this .sourceKey = Preconditions.checkNotNull(sourceKey); this .alternateKeys = Preconditions.checkNotNull(alternateKeys); this .fetcher = Preconditions.checkNotNull(fetcher); } } @Nullable LoadData<Data> buildLoadData (@NonNull Model model, int width, int height, @NonNull Options options) ; boolean handles (@NonNull Model model) ; }
ModelLoader 有两个方法,它们的作用在代码中已经说明了。LoadData 是 ModelLaoder 的内部类,它的内部有一个 DataFetcher 对象,从名字就能知道它的作用是数据的携带者,它用来对数据实行懒加载。我们看下 DataFetcher 的定义:
[->DataFetcher.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public interface DataFetcher <T> { interface DataCallback <T> { void onDataReady (@Nullable T data) ; void onLoadFailed (@NonNull Exception e) ; } void loadData (@NonNull Priority priority, @NonNull DataCallback<? super T> callback) ; void cleanup () ; void cancel () ; @NonNull Class<T> getDataClass () ; @NonNull DataSource getDataSource () ; }
容易知道,它的 loadData() 方法就是用来加载数据的,当数据加载完成后它通过 DataCallback 将结果返回给调用者。现在我们可以理解为什么它对数据的加载被称为懒加载了,因为 ModelLoader 构建出 LoadData 这个过程根本没有发生数据的加载,数据的真正加载是调用 DataFetcher#load() 实现的。
现在我们回到 DecodeJob 中,我们接着分析它的 runGenerators() 方法:
[->DecodeJob.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 private void runGenerators () { currentThread = Thread.currentThread(); startFetchTime = LogTime.getLogTime(); boolean isStarted = false ; while (!isCancelled && currentGenerator != null && !(isStarted = currentGenerator.startNext())) { stage = getNextStage(stage); currentGenerator = getNextGenerator(); if (stage == Stage.SOURCE) { reschedule(); return ; } } if ((stage == Stage.FINISHED || isCancelled) && !isStarted) { notifyFailed(); } }
这个方法的核心逻辑是取出一个 Stage,根据该 Stage 返回相应的 DataFetcherGenerator 并执行其 startNext() 方法,然后再取出下一个 Stage……如此循环。
其中 ResourceCacheGenerator 和 DataCacheGenerator 的资源获取方式都是从磁盘缓存中获取,不同的是,前者是从压缩和变换后的图片缓存中获取,后者是从原始图片数据缓存中获取。而 SourceGenerator 获取资源的方式则是从资源的原始位置获取,比如网络。这三者的工作原理大同小异,这里我们只分析 SourceGenerator#startNext() 方法:
[->SourceGenerator.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Override public boolean startNext () { ...... loadData = null ; boolean started = false ; while (!started && hasNextModelLoader()) { loadData = helper.getLoadData().get(loadDataListIndex++); if (loadData != null && (helper.getDiskCacheStrategy().isDataCacheable(loadData.fetcher.getDataSource()) || helper.hasLoadPath(loadData.fetcher.getDataClass()))) { started = true ; loadData.fetcher.loadData(helper.getPriority(), this ); } } return started; }
helper 是 DecodeHelper 对象,DecodeHelper 是一个帮助类,其实就是把原本属于 DecodeJob 的某些属性和方法抽离出去得到的类,估计是作者重构时新添的类,用来减轻 DecodeJob 的工作。它的 getLoadData() 是什么意思呢?我们根据代码来分析下:
[->DecodeHelper.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 List<LoadData<?>> getLoadData() { if (!isLoadDataSet) { isLoadDataSet = true ; loadData.clear(); List<ModelLoader<Object, ?>> modelLoaders = glideContext.getRegistry().getModelLoaders(model); for (int i = 0 , size = modelLoaders.size(); i < size; i++) { ModelLoader<Object, ?> modelLoader = modelLoaders.get(i); LoadData<?> current = modelLoader.buildLoadData(model, width, height, options); if (current != null ) { loadData.add(current); } } } return loadData; }
这个方法返回的是一个 LoadData 集合,这个集合是如何得到的呢?在 for 循环中,遍历上一步得到的 ModelLoader 列表,逐个调用其 buildLoadData() 方法,将得到的 LoadData 添加到结果中。这些 ModelLoader 是通过 Register#getModelLoader() 得到的,这个方法的内部实现虽然繁琐但是很简单:从 Register 中筛选所有能够处理该 Model 的 ModelLoader。筛选的依据就是 ModelLoader#handles() 的返回值,这点之前已经讲过了。Register 是一个注册中心,它会将所有的 ModelLoader,ResourceDecoder 和 ResourceTranscoder 在 Glide 初始化时注册进去。我们摘取部分代码来看:
[->Glide.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 registry .append(ByteBuffer.class, new ByteBufferEncoder ()) .append(InputStream.class, new StreamEncoder (arrayPool)) .append(Registry.BUCKET_BITMAP, InputStream.class, Bitmap.class, streamBitmapDecoder) .append(Bitmap.class, Bitmap.class, UnitModelLoader.Factory.<Bitmap>getInstance()) .append( Registry.BUCKET_BITMAP, Bitmap.class, Bitmap.class, new UnitBitmapDecoder ()) .append( Registry.BUCKET_BITMAP_DRAWABLE, ByteBuffer.class, BitmapDrawable.class, new BitmapDrawableDecoder <>(resources, byteBufferBitmapDecoder)) .append(BitmapDrawable.class, new BitmapDrawableEncoder (bitmapPool, bitmapEncoder)) .append( Registry.BUCKET_GIF, InputStream.class, GifDrawable.class, new StreamGifDecoder (registry.getImageHeaderParsers(), byteBufferGifDecoder, arrayPool)) .append( GifDecoder.class, GifDecoder.class, UnitModelLoader.Factory.<GifDecoder>getInstance()) .append(Uri.class, Drawable.class, resourceDrawableDecoder) .append( Uri.class, Bitmap.class, new ResourceBitmapDecoder (resourceDrawableDecoder, bitmapPool)) .append(File.class, InputStream.class, new FileLoader .StreamFactory()) .append(File.class, File.class, new FileDecoder ()) .append(File.class, File.class, UnitModelLoader.Factory.<File>getInstance()) .register(new InputStreamRewinder .Factory(arrayPool)) .append(int .class, InputStream.class, resourceLoaderStreamFactory) .append(int .class, Uri.class, resourceLoaderUriFactory) .append(String.class, InputStream.class, new StringLoader .StreamFactory()) .append(Uri.class, InputStream.class, new HttpUriLoader .Factory()) .append(Uri.class, File.class, new MediaStoreFileLoader .Factory(context)) .append(byte [].class, ByteBuffer.class, new ByteArrayLoader .ByteBufferFactory()) .append(byte [].class, InputStream.class, new ByteArrayLoader .StreamFactory()) .append(Uri.class, Uri.class, UnitModelLoader.Factory.<Uri>getInstance()) .append(Drawable.class, Drawable.class, UnitModelLoader.Factory.<Drawable>getInstance()) .append(Drawable.class, Drawable.class, new UnitDrawableDecoder ()) .register( Bitmap.class, BitmapDrawable.class, new BitmapDrawableTranscoder (resources)) .register(Bitmap.class, byte [].class, bitmapBytesTranscoder) .register( Drawable.class, byte [].class, new DrawableBytesTranscoder ( bitmapPool, bitmapBytesTranscoder, gifDrawableBytesTranscoder)) .register(GifDrawable.class, byte [].class, gifDrawableBytesTranscoder);
由于代码太长,我只贴了部分注册内容。上面这些代码应该很容易看懂,几乎每个注册方法都会接受两个 Class 类型的对象和一个 ModelLoader 或者 ResourceDecoder 或者 ResourceTranscoder 对象,表示该 ModelLoader 或者 ResourceDecoder 或者 ResourceTranscoder 对象能够实现哪两种资源类型的转换。可以用下图来表示资源的类型变化过程:
由上图可知,如果无法找到一组 (ModelLoader, ResourceDecoder, ResourceTranscoder),使得资源类型由 Model 转换到 Transcoded Resource,那么加载便会失败。反之,可能有多组 (ModelLoader, ResourceDecoder, ResourceTranscoder) 能够实现 Model 到 Transcoded Resource 的转换。
现在回到 SourceGenerator#startNext():
[->SourceGenerator.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Override public boolean startNext () { ...... loadData = null ; boolean started = false ; while (!started && hasNextModelLoader()) { loadData = helper.getLoadData().get(loadDataListIndex++); if (loadData != null && (helper.getDiskCacheStrategy().isDataCacheable(loadData.fetcher.getDataSource()) || helper.hasLoadPath(loadData.fetcher.getDataClass()))) { started = true ; loadData.fetcher.loadData(helper.getPriority(), this ); } } return started; }
通过前面的分析我们知道,DecodeHelper#getLoadData() 返回的是所有能够处理 Model 对象的 ModelLoader 构建出的 LoadData 的集合。循环体中做的事就是选择第一个满足条件的 LoadData,用它内部的 DataFetcher 对象来加载出 Data。之前在分析 DataFetcher 的时候讲过,它的 loadData() 方法会通过 DataCallback 将 Data 传回调用者。在这里调用者就是 SourceGenerator,它实现了 DataCallback 中的方法:
[->SourceGenerator.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Override public void onDataReady (Object data) { DiskCacheStrategy diskCacheStrategy = helper.getDiskCacheStrategy(); if (data != null && diskCacheStrategy.isDataCacheable(loadData.fetcher.getDataSource())) { dataToCache = data; cb.reschedule(); } else { cb.onDataFetcherReady(loadData.sourceKey, data, loadData.fetcher, loadData.fetcher.getDataSource(), originalKey); } } @Override public void onLoadFailed (@NonNull Exception e) { cb.onDataFetcherFailed(originalKey, e, loadData.fetcher, loadData.fetcher.getDataSource()); }
我们重点分析 onDataReady() 方法,这个方法会根据回调所在的线程选择不同的执行路径,这里我们假设走到了 else 块中,那么 FetcherReadyCallback#onDataFetcherReady() 会得到调用。FetcherReadyCallback 也是一个回调接口,它的是实现者是 DecodeJob。这样一来,Data 便从 SourceGenerator 传到了 DecodeJob 中,我们现在看看 DecodeJob#onDataFethcerReady():
[->DecodeJob.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Override public void onDataFetcherReady (Key sourceKey, Object data, DataFetcher<?> fetcher, DataSource dataSource, Key attemptedKey) { this .currentSourceKey = sourceKey; this .currentData = data; this .currentFetcher = fetcher; this .currentDataSource = dataSource; this .currentAttemptingKey = attemptedKey; if (Thread.currentThread() != currentThread) { runReason = RunReason.DECODE_DATA; callback.reschedule(this ); } else { TraceCompat.beginSection("DecodeJob.decodeFromRetrievedData" ); try { decodeFromRetrievedData(); } finally { TraceCompat.endSection(); } } }
这里同样会根据回调所在线程的不同执行不同的操作,但是最终都会调用到 decodeFromRetrievedData 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 private void decodeFromRetrievedData () { if (Log.isLoggable(TAG, Log.VERBOSE)) { logWithTimeAndKey("Retrieved data" , startFetchTime, "data: " + currentData + ", cache key: " + currentSourceKey + ", fetcher: " + currentFetcher); } Resource<R> resource = null ; try { resource = decodeFromData(currentFetcher, currentData, currentDataSource); } catch (GlideException e) { e.setLoggingDetails(currentAttemptingKey, currentDataSource); throwables.add(e); } if (resource != null ) { notifyEncodeAndRelease(resource, currentDataSource); } else { runGenerators(); } }
decodeFromData() 返回了 Transcoded Resource 类型的的图片资源。这个方法的内部细节即使不去分析我们也能略知一二,无非就是对 Data 使用合适的 ResourceDocoder 和 ResourceTranscoder 进行解码和转码。这个方法的最后调用了 notifyEncodeAndRelease(),这个方法最终会调用 DecodeJob.Callback#onResourceReady() 将最终的资源回传。EncodeJob 实现了该接口并且在构造 DecodeJob 时曾将自身作为参数传入,因此资源会被传入 EncodeJob#onResourceReady() 中。类似的 EncodeJob 又会通过回调将资源进一步传给 SingleRequest 中,SingleRequest 最后通过 Target#onResourceReady() 结果传给了 Target。
补充 前面我们仅仅是沿着加载这条主线讲解了 Glide 内部原理,为了不使逻辑混乱,很多细节我们都带过了。为了加深对 Glide 的理解,我觉得有些问题还是有必要分析一下。
Glide 是如何暂停加载任务的 我们知道 Glide 会借助 Activity 或者 Fragment 的生命周期来管理加载,那么具体它是如何再暂停和继续一个正在线程池中运行的加载任务呢?之前在分析 Engine#load() 的时候,对于它的返回值我暂时没讲,现在我们回到 Engine#load() 方法:
[->Engine.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 EngineKey key = keyFactory.buildKey(model, signature, width, height, transformations, resourceClass, transcodeClass, options); EngineResource<?> active = loadFromActiveResources(key, isMemoryCacheable); if (active != null ) { cb.onResourceReady(active, DataSource.MEMORY_CACHE); ...... return null ; } EngineResource<?> cached = loadFromCache(key, isMemoryCacheable); if (cached != null ) { cb.onResourceReady(cached, DataSource.MEMORY_CACHE); ...... return null ; } EngineJob<?> current = jobs.get(key, onlyRetrieveFromCache); if (current != null ) { current.addCallback(cb); ...... return new LoadStatus (cb, current); } EngineJob<R> engineJob = engineJobFactory.build(key, isMemoryCacheable, useUnlimitedSourceExecutorPool, useAnimationPool, onlyRetrieveFromCache); DecodeJob<R> decodeJob = decodeJobFactory.build(glideContext, model, key, signature, width, height, resourceClass, transcodeClass, priority, diskCacheStrategy, transformations, isTransformationRequired, isScaleOnlyOrNoTransform, onlyRetrieveFromCache, options, engineJob); jobs.put(key, engineJob); engineJob.addCallback(cb); engineJob.start(decodeJob); ...... return new LoadStatus (cb, engineJob);
我们知道它的返回值是 LoadStatus 对象,这个类的定义如下:
[->Engine.java]
1 2 3 4 5 6 7 8 9 10 11 public static class LoadStatus { private final EngineJob<?> engineJob; private final ResourceCallback cb; LoadStatus(ResourceCallback cb, EngineJob<?> engineJob) { this .cb = cb; this .engineJob = engineJob; } public void cancel () { engineJob.removeCallback(cb); } }
很简单,仅仅是封装了 EngineJob 和 ResourceCallback 两个对象。注意到他还有一个 cancel() 方法,这个方法的作用我想大家猜也能猜到,它是用来取消加载的。那么这个方法什么时候会调用呢?我们得回到 SingleRequest 中去寻找答案,因为 Engine#load() 是在 SingleRequest 中调用的,LoadStatus 对象肯定是要返回给 SingleRequest 的。
[->SingleRequest.java]
1 loadStatus = engine.load(...);
SingleRequest 将返回的 LoadStatus 保存在了 loadStatus 中,现在我们看看 SingleRequest 的 pause() 方法,这个方法会在 RequestTracker#pauseRequests() 中调用,而 RequestTracker#pauseRequests() 会被 RequestManager#onStop() 触发:
[->SingleRequest.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 @Override public void pause () { clear(); status = Status.PAUSED; } @Override public void clear () { ...... if (status == Status.CLEARED) { return ; } cancel(); ...... status = Status.CLEARED; } void cancel () { assertNotCallingCallbacks(); stateVerifier.throwIfRecycled(); target.removeCallback(this ); status = Status.CANCELLED; if (loadStatus != null ) { loadStatus.cancel(); loadStatus = null ; } }
pause() 方法最后会导致 loadStatus 的 cancel() 方法被调用,现在我们从 LoadStatus#cancel() 方法往下看,为什么 cancel() 就能将一个正在运行的加载任务给取消掉呢?LoadStatus#cancel() 只是简单调用了 EngineJob#removeCallback():
[->EngineJob.java]
1 2 3 4 5 6 7 8 9 10 11 12 void removeCallback (ResourceCallback cb) { Util.assertMainThread(); stateVerifier.throwIfRecycled(); if (hasResource || hasLoadFailed) { addIgnoredCallback(cb); } else { cbs.remove(cb); if (cbs.isEmpty()) { cancel(); } } }
这个方法的意图很明了,假设加载还未完成的时候取消了加载,那么便会执行 else 中的代码块,从回调列表中删除该 ResourceCallback,但是移除还不够,因为移除回调仅仅是让 SingleRequest 接收不到最终的结果,我们还必须停止加载任务以节省资源。接下来会继续判断回调列表是否为空,如果为空就调用 cancel() 方法,这个方法就是用来取消加载任务的。这样看来,单单取消一个加载请求并不一定会导致这个加载任务的取消,这很容易理解,因为可能还有其他的请求依赖这个任务的执行。现在看看 EngineJob#cancel() 方法:
[->Engine.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 void cancel () { if (hasLoadFailed || hasResource || isCancelled) { return ; } isCancelled = true ; decodeJob.cancel(); listener.onEngineJobCancelled(this , key); } public void cancel () { isCancelled = true ; DataFetcherGenerator local = currentGenerator; if (local != null ) { local.cancel(); } }
这个方法调用了 DecodeJob#cancel(),DecodeJob#cancel() 做了两件事,一是设置 isCancelled 为 true,二是停止当前 DataFetcherGenerator 中的任务。isCancelled 是一个标志,那么它对加载任务有什么影响呢?影响主要有两处,一个 DecodeJob#run(),另一个是 DecodeJob#runGenerators()。isCancelled==true 会导致前者发出加载失败的通知,导致后者停止运行后续的 DataFetcherGenerator 并发出加载失败的通知。加载失败的通知最终会传到 EngineJob 中,使得 EngineJob 执行资源的释放工作。
有一个细节不知大家发现没有,DecodeJob 是被投入线程中运行的,也就是说 SingleRequest 和 DecodeJob 是在不同的线程中运行的。isCancelled 的改变是在 SingleRequest 的线程中进行的,而 DecodeJob 读取 isCancelled 的值是在 DecodeJob 的线程中发生的。那么这很容易发生一个问题,就是线程感知问题。那么 Glide 是如何解决这一问题的呢?我们看看 isCancelled 在 DecodeJob 中的定义:
[->DecodeJob.java]
1 private volatile boolean isCancelled;
Glide 给 isCancelled 加了 volatile 关键字,这样保证了,SingleRequest 线程对 isCancelled 的改变能够及时被 DecodeJob 线程感知。同样的,currentGenerator 在定义时也使用了这个关键字,目的都是一样的。如果大家对于 volatile 关键字还不理解,可以到网上查阅相关资料,因为一时半会儿是解释不清的,我当初为了理解这个关键字花了不少时间。
ModelLoader 的内部细节 ModelLoader 的子类有很多,Glide 会根据 model 的类型决定使用哪种 ModelLoader。现假设 model 为 http 协议的 url 的话,Glide 最终就会用到 HttpGlideUrlLoader 实现 Model 到 Data 的转换。
[->HttpGlideUrlLoader]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 public class HttpGlideUrlLoader implements ModelLoader <GlideUrl, InputStream> { public static final Option<Integer> TIMEOUT = Option.memory( "com.bumptech.glide.load.model.stream.HttpGlideUrlLoader.Timeout" , 2500 ); @Nullable private final ModelCache<GlideUrl, GlideUrl> modelCache; public HttpGlideUrlLoader () { this (null ); } public HttpGlideUrlLoader (@Nullable ModelCache<GlideUrl, GlideUrl> modelCache) { this .modelCache = modelCache; } @Override public LoadData<InputStream> buildLoadData (@NonNull GlideUrl model, int width, int height, @NonNull Options options) { GlideUrl url = model; if (modelCache != null ) { url = modelCache.get(model, 0 , 0 ); if (url == null ) { modelCache.put(model, 0 , 0 , model); url = model; } } int timeout = options.get(TIMEOUT); return new LoadData <>(url, new HttpUrlFetcher (url, timeout)); } @Override public boolean handles (@NonNull GlideUrl model) { return true ; } public static class Factory implements ModelLoaderFactory <GlideUrl, InputStream> { private final ModelCache<GlideUrl, GlideUrl> modelCache = new ModelCache <>(500 ); @NonNull @Override public ModelLoader<GlideUrl, InputStream> build (MultiModelLoaderFactory multiFactory) { return new HttpGlideUrlLoader (modelCache); } @Override public void teardown () { } } }
重点是 HttpUrlFethcer,它的 loadData() 方法会调用 loadDataWithRedirects():
[->HttpUrlFetcher.java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 private InputStream loadDataWithRedirects (URL url, int redirects, URL lastUrl, Map<String, String> headers) throws IOException { ..... urlConnection = connectionFactory.build(url); for (Map.Entry<String, String> headerEntry : headers.entrySet()) { urlConnection.addRequestProperty(headerEntry.getKey(), headerEntry.getValue()); } urlConnection.setConnectTimeout(timeout); urlConnection.setReadTimeout(timeout); urlConnection.setUseCaches(false ); urlConnection.setDoInput(true ); ...... urlConnection.setInstanceFollowRedirects(false ); urlConnection.connect(); if (isCancelled) { return null ; } final int statusCode = urlConnection.getResponseCode(); if (statusCode / 100 == 2 ) { return getStreamForSuccessfulRequest(urlConnection); } else if (statusCode / 100 == 3 ) { String redirectUrlString = urlConnection.getHeaderField("Location" ); if (TextUtils.isEmpty(redirectUrlString)) { throw new HttpException ("Received empty or null redirect url" ); } URL redirectUrl = new URL (url, redirectUrlString); return loadDataWithRedirects(redirectUrl, redirects + 1 , url, headers); } else if (statusCode == -1 ) { throw new HttpException (statusCode); } else { throw new HttpException (urlConnection.getResponseMessage(), statusCode); } }
这里就是 Glide 和网络交互的地方,Glide 通过 HttpUrlConnection 进行网络连接,并且对可能存在的重定向情况进行了处理,HttpUrlFetcher 最终会将获取到的 InputStream 作为 Data 返回。
总结 以上便是 Glide 的加载流程,它内部的运作实在是太复杂了,但正是这种复杂的内部实现使得 Glide 的可扩展型得到增强。比如我们可以自定义磁盘缓存策略,自定义 ModelLoader 以实现 Model 到 Data 的转换,也可以自定义 ResourceDecoder 和 ResourceTranscoder 来实现资源的解码和转码。最后,我们用一张图来总结整个加载过程: